





 Office
Office Benefit & Welfare
Benefit & Welfare Event
Event Training
TrainingLịch Sử và Tương Lai của Tìm Kiếm: Từ Inverted Index đến Semantic Search
June 28, 2024
Trong thế giới số ngày nay, việc tìm kiếm và truy xuất thông tin đã trải qua một hành trình dài, từ việc phát minh ra chỉ mục đảo ngược (Inverted Index) đến các mô hình ngôn ngữ lớn (LLMs) như BERT và GPT. Bài tech blog này sẽ đưa bạn qua hành trình đó và làm sáng tỏ cách các công nghệ mới đang cải tiến cách chúng ta tương tác với dữ liệu.
Từ Ghi Chép Kiến Thức đến Inverted Index
Lịch sử của việc tìm kiếm bắt đầu từ nhu cầu ghi chép kiến thức của con người. Việc tạo danh sách thuật ngữ và liên kết chúng với các trang xuất hiện đã đánh dấu bước đầu của chỉ mục đảo ngược (Inverted Index).
 Phụ lục cuối sách - phiên bản sơ khai của Inverted Index (nguồn: qdrant.tech)
Phụ lục cuối sách - phiên bản sơ khai của Inverted Index (nguồn: qdrant.tech)
Đây là cấu trúc dữ liệu cơ bản cho phép truy xuất nhanh chóng các tài liệu chứa thuật ngữ cụ thể. Quá trình số hóa đã làm cho việc này trở nên dễ dàng hơn, nhưng nguyên tắc cơ bản vẫn không thay đổi.
Ví dụ, trong Database lưu 2 bản ghi (record) sau:
- #1. Trọng Phúc, đẹp trai nhưng nghèo
- #2. Mark Zuckerberg, xấu trai nhưng giàu
Thì Database sẽ có thể đánh index cho các từ quan trọng, và khi tìm kiếm, câu truy vấn (query) khớp với từ index nào, sẽ tìm ra bản ghi (record) tương ứng.
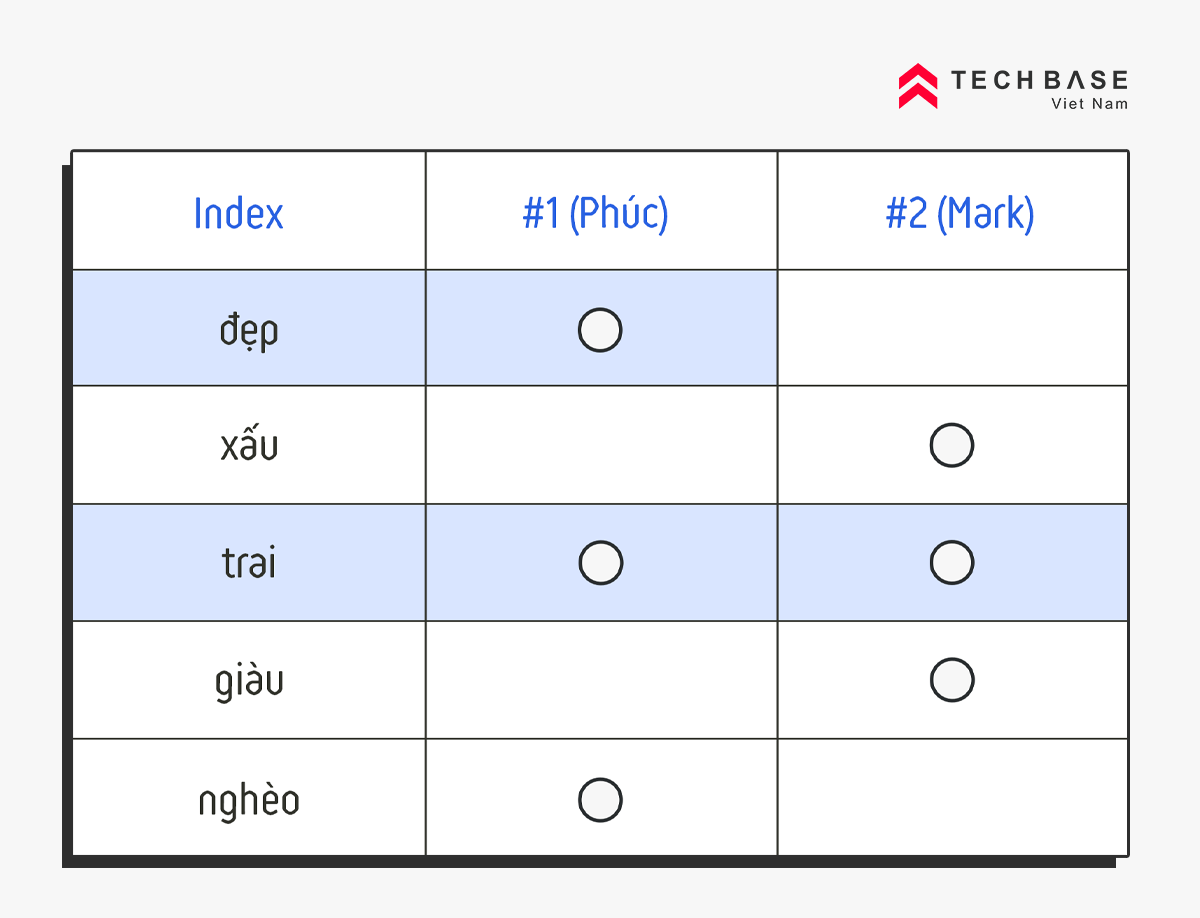 Tìm kiếm với từ khóa "trai đẹp", sẽ chỉ tìm thấy "#1 Phúc".
Tìm kiếm với từ khóa "trai đẹp", sẽ chỉ tìm thấy "#1 Phúc".
Thời gian trôi qua, và chúng ta không có nhiều thay đổi trong kĩ thuật tìm kiếm trong một thời gian khá dài. Nhưng lượng dữ liệu văn bản của chúng ta ngày càng phát triển nhanh hơn. Đã có 1 vài kỹ thuật được áp dụng, nhưng cơ bản, bạn phải biết từ khóa chính xác thì mới tìm được thứ mình muốn.
Làm thế nào chúng ta có thể vượt qua những giới hạn này? Làm sao để tìm kiếm thông tin mà không chỉ dựa vào từ khóa cụ thể? Và làm sao chúng ta có thể xử lý sự bùng nổ của dữ liệu văn bản?
Vượt Qua Giới Hạn với Vector Thưa
Câu trả lời nằm ở việc sử dụng Vector Thưa (Sparse Vectors). Bằng cách mã hóa tài liệu và truy vấn thành các vector mà mỗi vị trí tương ứng với một từ trong từ điển, chúng ta không chỉ tìm kiếm tài liệu có chứa từ khóa một cách hiệu quả mà còn mở rộng quy mô dữ liệu mà không làm giảm hiệu suất tìm kiếm.
 Vector với độ dài của 1 cuốn tử điển, những vị trí khớp với từ trong văn bản gốc sẽ mang giá trị 1, toàn bộ các vị trí khác mang giá trị 0.
Vector với độ dài của 1 cuốn tử điển, những vị trí khớp với từ trong văn bản gốc sẽ mang giá trị 1, toàn bộ các vị trí khác mang giá trị 0.
Hình ảnh trên mô tả một ví dụ về truy vấn được vector hóa theo định dạng thưa. Trong hình, từ "Phúc", "đẹp" và "trai" được biểu diễn bằng các giá trị 1.0 tại vị trí tương ứng của chúng trong vector, trong khi các từ khác trong từ điển không xuất hiện trong truy vấn đều có giá trị 0.0. Điều này minh họa cho việc sử dụng các vector thưa để biểu diễn dữ liệu văn bản, nơi chỉ những từ xuất hiện mới được ghi nhận, giúp tối ưu hóa việc lưu trữ và xử lý.
Việc mã hóa tài liệu và truy vấn thành các vector với mỗi vị trí tương ứng với một từ trong từ điển, đã mở rộng quy mô dữ liệu mà không làm giảm hiệu suất tìm kiếm. Tuy nhiên, việc loại bỏ sự phụ thuộc vào từ khóa chính xác vẫn chưa làm được.
 Các từ khác nhau nhưng cùng ý nghĩa vẫn chưa thể tìm được mối liên hệ với kỹ thuật tìm kiếm truyền thống.
Các từ khác nhau nhưng cùng ý nghĩa vẫn chưa thể tìm được mối liên hệ với kỹ thuật tìm kiếm truyền thống.
Vector Dày Đặc và Tìm Kiếm Ngữ Nghĩa
Chúng ta đã tìm ra câu trả lời thông qua Vector Dày Đặc (Dense Vectors), được tạo ra bởi các mô hình ngôn ngữ lớn như BERT và GPT. Các vector này nắm bắt được ý nghĩa ngôn ngữ một cách sâu sắc và toàn diện hơn. Không giống như vector thưa, vector dày đặc chứa ít giá trị 0, và đại diện cho một lượng lớn thông tin trong một không gian vector nhỏ hơn, cho phép chúng ta hiểu và xử lý ngôn ngữ một cách linh hoạt và đa dạng. Ngoài các từ "chính xác" với văn bản mang giá trị 1, các từ "có liên quan về mặt ngữ nghĩa" cũng mang giá trị lớn hơn 0.
Ngoài các từ "chính xác" với văn bản mang giá trị 1, các từ "có liên quan về mặt ngữ nghĩa" cũng mang giá trị lớn hơn 0.
Vector dày đặc, được tạo ra bởi các mô hình ngôn ngữ lớn, đã giải quyết nhiều hạn chế của vector thưa. Chúng nắm bắt được ý nghĩa ngôn ngữ một cách sâu sắc hơn và cho phép tìm kiếm dựa trên sự tương đồng của các vector.
 So sánh với Sparse Vector, Dense Vector chứa nhiều thông tin ngữ nghĩa hơn. Vì nhiều thông tin hơn nên nó được gọi là vector dày đặc (dense).
So sánh với Sparse Vector, Dense Vector chứa nhiều thông tin ngữ nghĩa hơn. Vì nhiều thông tin hơn nên nó được gọi là vector dày đặc (dense).
Một lợi thế nữa của Vector Dày Đặc, là nó tận dụng được độ dài của high-dimension vector.
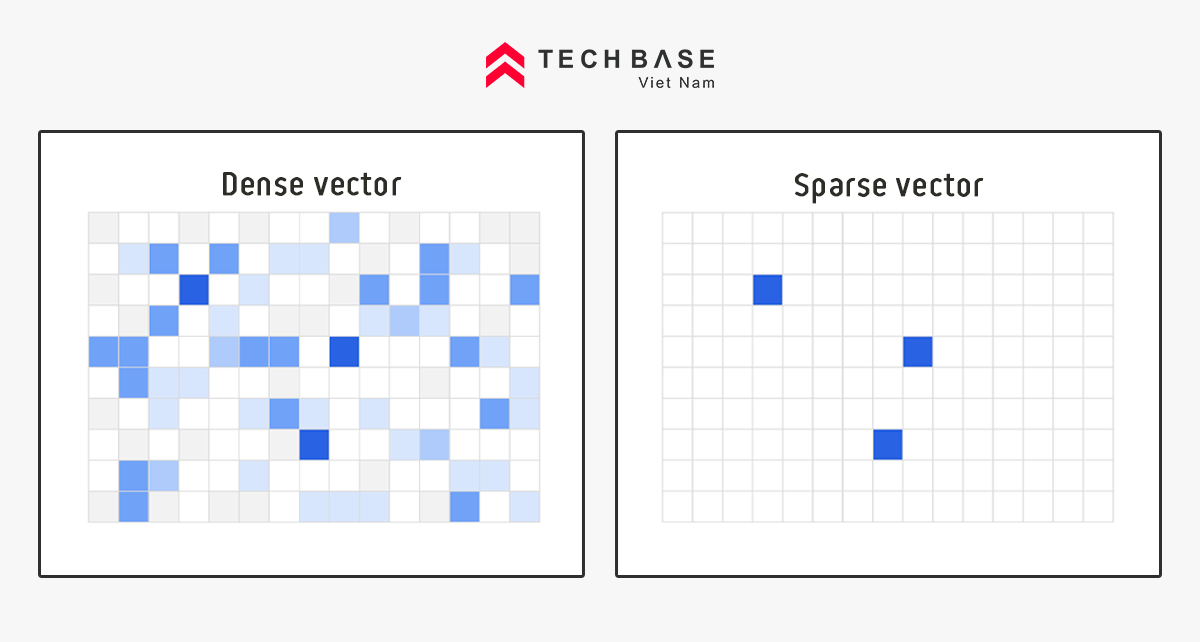 Một cách biểu diễn khác để thấy mật độ thông tin của Vector Dày Đặc nhiều hơn Vector Thưa.
Một cách biểu diễn khác để thấy mật độ thông tin của Vector Dày Đặc nhiều hơn Vector Thưa.
Và khả năng lưu trữ thông tin ngữ nghĩa này, mở ra một phương phá tìm kiếm mới - Tìm Kiếm Theo Ngữ Cảnh (Semantic Search)
Semantic Search
Quay trở lại với 2 câu này:
 Với phương pháp tìm kiếm truyền thống, thì 2 câu này là khác nhau.
Với phương pháp tìm kiếm truyền thống, thì 2 câu này là khác nhau.
Nhưng nhờ sức mạnh của LLM, đã "biến" các văn bản thành Dense Vector, việc thì 2 câu trên là "tương đồng" về mặt ý nghĩa, khi nhìn vào giá trị của các vector.
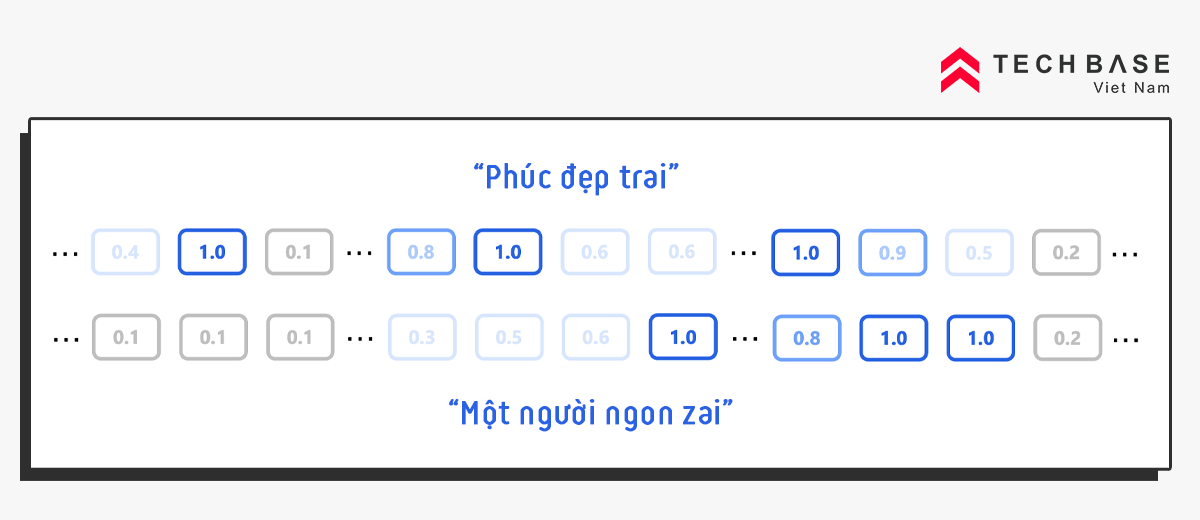
Lúc này, việc so sánh 2 văn bản, sẽ trở thành việc so sánh 2 vector. Nên có thể áp dụng các thuật toán thống kê cơ bản để "tính toán độ tương đồng", như là Cosine Similarity.
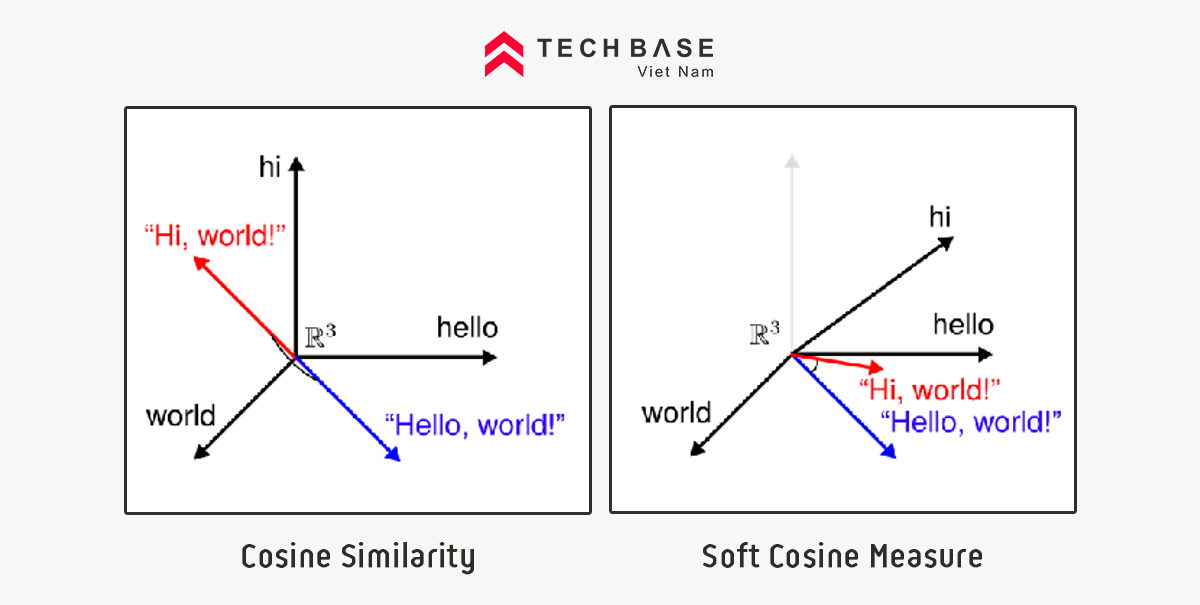 1 ví dụ đơn giản của so sánh 2 vector trong không gian 3 chiều.
1 ví dụ đơn giản của so sánh 2 vector trong không gian 3 chiều.
Tìm kiếm ngữ nghĩa (Semantic Search) không chỉ là một bước tiến trong công nghệ tìm kiếm; nó là một cuộc cách mạng trong cách chúng ta tương tác với dữ liệu. Không giống như tìm kiếm truyền thống dựa trên từ khóa, tìm kiếm ngữ nghĩa tập trung vào ý nghĩa đằng sau từng truy vấn, cho phép trả về kết quả chính xác hơn dựa trên ngữ cảnh thực sự của thông tin. Điều này giúp người dùng trải nghiệm một cách tìm kiếm tự nhiên, gần giống với cách chúng ta tương tác và trao đổi thông tin trong cuộc sống hàng ngày.
Ứng dụng Semantic Search
Phát minh ra 1 kỹ thuật mới là một chuyện, còn đem nó vào giải quyết 1 vấn đề cụ thể như thế nào, thì là một chuyện khác.
Hãy tiếp tục theo dõi ở bài tiếp theo: RAG: Retrieval-Augmented Generation (tech blog version)